.jpg)
Repetition. In a workout, it’s a good thing. When giving a speech, not so much. In programming, it can be down-right terrible, needlessly inflating our code, making it unreadable, and worst of all, it can lead to hard-to-find errors, especially in nearly identical blocks of code that differ only on some small value or command.
Fortunately, our programming forefathers solved this issue long ago with the basic coding building blocks of variables, parameters, and templates. However, in some areas, such as Databricks deployments, developers sometimes overlook these basic concepts, leading to… that’s correct, unnecessary repetition.
At Brightly, we try to set such oversights right. Read on to see how you can use dbx and Jinja templates to avoid duplicating code in Databricks deployments.
Background
Databricks, the increasingly popular all-in-one data platform, offers a variety of solutions for different aspects of data pipelines, including orchestration, storage, and transformations. Perhaps the easiest way to deploy data pipelines to Databricks is to use dbx, a.k.a. Databricks CLI eXtensions. dbx lets you define data pipelines as code and add them to version control. These pipeline definitions include which steps to execute, when to execute them, and which computational resources to use.
In this article, we’ll take a closer look at how we can use dynamic templating to simplify and streamline the management of Databricks deployments. In Databricks deployments, we can avoid code (and effort) duplication by using the same basic workflow definitions in several environments, e.g., development and production, and making only the minor changes required by each environment, for example, regarding access rights.
Databricks deployments using dbx
Let’s start with a few words about Databricks deployments with dbx. At a minimum, a dbx project includes a deployment file that defines the execution steps and clusters (i.e., computational resources), source files required for transformation steps (e.g., Python notebooks), and a “project.json” configuration file that defines, for example, which Databricks CLI tokens to use for authentication in each environment.
dbx-demo-project/
├─.dbx/
│ ├─ project.json
├─ conf/
│ ├─ deployment.yaml
├─ notebooks/
│ ├─ sample_dlt_notebook.py
A dbx deployment creates (or updates) Databricks workflows. When running the ”dbx deploy --environment <env>” command, dbx searches the “conf” folder for the ”deployment” file, builds the project if needed, and, lastly, updates the workflows in the given environment to match those defined in the deployment file. Based on workflow type, dbx transfers the workflow definition to Databricks via the Jobs API or the Delta Live Tables (DLT) Pipelines API.
OK. It’s time to get our hands dirty and have a look at a minimalistic DLT pipeline.
# conf/deployment.yaml (link to gist)
build:
no_build: true
environments:
dev:
workflows:
- name: "dbx-dlt-demo-pipeline"
workflow_type: "pipeline"
target: "demo-db"
libraries:
- notebook:
path: "/Some/path/notebooks/sample_dlt_notebook"
# Multi-task workflow for orchestrating the whole data pipeline
- name: "dbx-demo-job"
workflow_type: "job-v2.1"
tasks:
- task_key: "pipeline-task"
pipeline_task:
pipeline_id: "pipeline://dbx-dlt-demo-pipeline"
This deployment uses only one environment and has two workflows. The first is the Delta Live Tables pipeline which uses a Python notebook as the source code that defines the pipeline. The second is a Databricks job that executes the DLT pipeline we just defined. The benefit of this structure, that separates pipeline definition and orchestration, is that the Databricks job can execute multiple, previously defined, pipeline tasks and define their dependencies, as well as schedule execution and set alerts.
Now, let’s say we want to deploy these same workflows to different environments. The standard approach would be to duplicate the workflow definitions, as in the following code:
environments:
dev:
workflows:
# DLT pipeline
...
test:
workflows:
# The same DLT pipeline
...
prod:
workflows:
# The same DLT pipeline again
...
As we can see, this approach results in a cumbersome deployment file with unnecessary repetition. We could, of course, use YAML anchors and aliases to reference the DLT pipeline, which would be defined only once. However, as soon as a workflow needs to be customized, e.g., for a specific environment, trying to keep our YAML file readable and free of repetition becomes a real headache, if not impossible.
Another option could be to use dbx’s built-in support for Jinja variables that allows us to pass such variables to our deployment file. The issue is that this relates only to substituting actual values with parameters, and doesn’t help us evade having to repeat workflow definitions for each environment (click here for more information on native dbx support for Jinja variables). Also, when using dbx Jinja variables, we can’t actually view the fully rendered YAML deployment file (in which the parameters have been replaced with their appropriate values – file #3 in the image below), making deployments more difficult to debug.
Dbx with Jinja templating
Jinja is a templating engine that is used to insert dynamic content into document templates in various formats. It is probably most well-known for being used with Django, Flask, and Ansible.
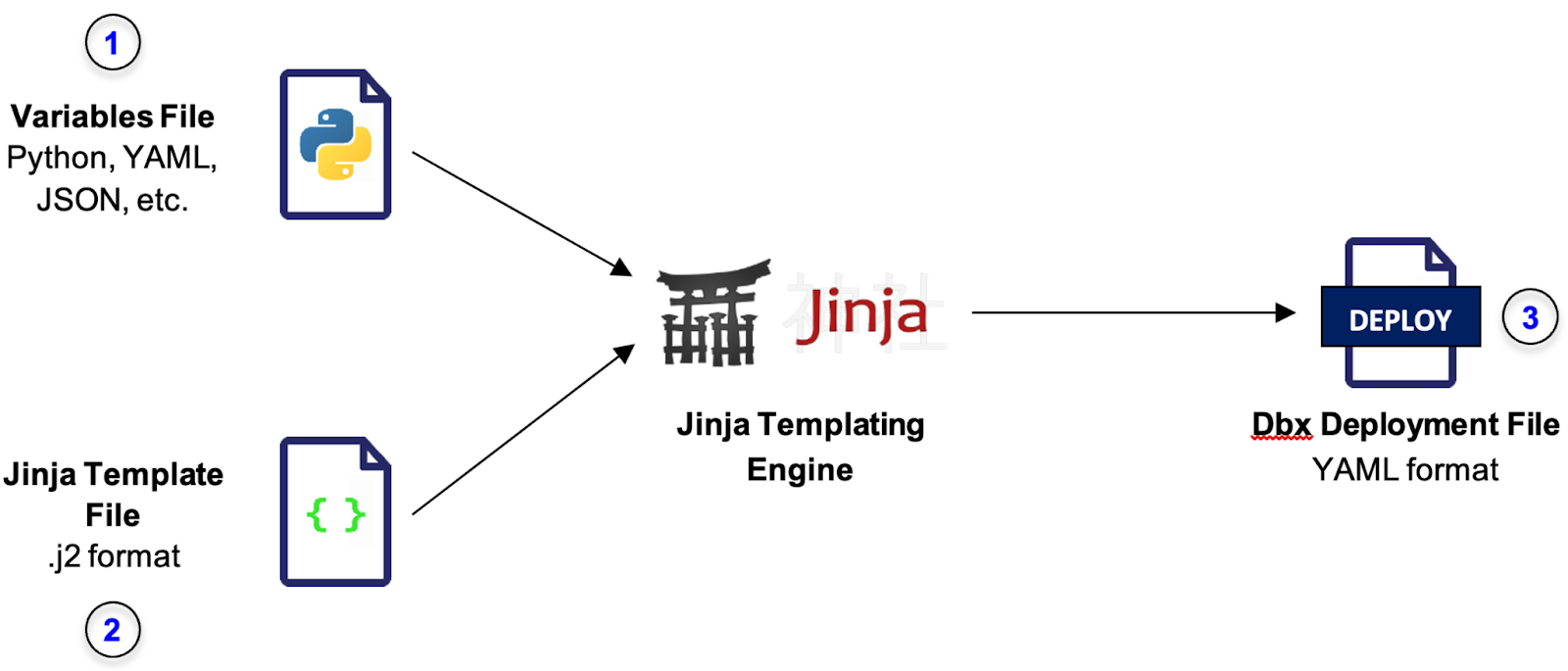
As depicted in the diagram above, in addition to the variables file(s) (1) and the deployment file (3), i.e., the rendered configuration file, Jinja2 adds a template file (2). The template file abstracts the structure of the deployment file by using Jinja variables as placeholders for blocks of code (and not just parameter values), where the code for each environment can be found in the variables file. In addition, in Jinja, we can see all files, including the deployment file, allowing us to double check and debug the file before deploying it.
In the case of Databricks, we will use Jinja to dynamically generate a dbx deployment file and avoid the aforementioned duplication of code.
Step 1
Start by installing Jinja:
pip install jinja2
Step 2
Rename the "deployment.yaml” file to “deployment.j2” (“j2” is the file extension for Jinja template files) and add a Python script to the file that will render our brand-new Jinja template back into YAML format.
# generate_deployment_file.py (link to gist)
import jinja2
from conf.deployment_variables import envs
templateLoader = jinja2.FileSystemLoader(searchpath="conf")
templateEnv = jinja2.Environment(loader=templateLoader, trim_blocks=True, lstrip_blocks=True)
template = templateEnv.get_template("deployment.j2")
template_out = template.render(envs=envs)
with open(f"conf/deployment.yaml", "w") as file:
file.write(template_out)
Step 3
Create a file named “conf/deployment_variables.py” that is used to pass parameters to the deployment template.
# conf/deployment_variables.py (link to gist)
envs = {
'dev': {
'policy_id': "0123456789012345",
'workflow_owner': "service-principal://some-service-principal-dev",
},
'test': {
'policy_id': "3456789012345678",
'workflow_owner': "service-principal://some-service-principal-test",
'failure_alerts': "failures-in-test@company.com",
},
'prod': {
'policy_id': "6789012345678901",
'workflow_owner': "service-principal://some-service-principal-prod",
'failure_alerts': "failures-in-prod@company.com",
}
}
In this example we have defined a unique cluster policy for each environment. Cluster policies simplify and standardize cluster creation by setting limits and defaults on the types of clusters users can create. We assign a service principal, representing one or more actual users, as the workflow owner. We recommend doing this because, by default, users cannot modify workflows created by other users. Finally, an email address (e.g., associated with a Teams channel) is provided where alerts about failed runs can be sent to.
Other settings you might want to configure for each environment:
- Cluster type: Node type and number of worker processes. Auto-scaling can be used to fine-tune the cluster to handle the required workload.
- Instance profiles to grant Databricks clusters executing the DLT pipelines access to environment specific S3 data.
- DLT development mode to enable faster development with reusable clusters in the dev environment.
- Database target and Delta Lake storage path.
- Workflow schedules.
Step 4
After creating the variables file, add Jinja syntax to the “deployment.j2” to obtain data from the “deployment_variables.py” file.
Note that the “generate_deployment_file.py” script passes the “envs” dictionary from “deployment_variables.py” to the Jinja template when rendering it with “template.render(envs=envs)”.
# conf/deployment.j2 (link to gist)
build:
no_build: true
environments:
{% for env, conf in envs.items() %}
{{ env }}:
workflows:
# DLT pipeline
- name: "dbx-dlt-demo-pipeline"
access_control_list:
- user_name: "{{ conf.get('workflow_owner') }}"
permission_level: "IS_OWNER"
target: "demo-db"
workflow_type: "pipeline"
clusters:
- policy_id: "{{ conf.get('policy_id') }}"
libraries:
- notebook:
path: "/Some/path/notebooks/sample_dlt_notebook"
# Workflow to orchestrate the whole data pipeline
- name: "dbx-demo-job"
workflow_type: "job-v2.1"
access_control_list:
- user_name: "{{ conf.get('workflow_owner') }}"
permission_level: "IS_OWNER"
{% if conf.get('failure_alerts') != None %}
email_notifications:
on_failure:
- "{{ conf.get('failure_alerts') }}"
{% endif %}
tasks:
- task_key: "pipeline-task"
pipeline_task:
pipeline_id: "pipeline://dbx-dlt-demo-pipeline"
{% endfor %}
Let’s briefly review the Jinja features we have just used:
- Loop “{% for env, conf in envs.items() %} … {% endfor %}” iterates through the environments defined in “deployment_variables.py”, rendering the template between the two blocks for each of the three environments defined in the file.
- Variable substitution is defined using double curly brackets. For example, in the first iteration of the “for” loop for the development environment, “{{ env }}” is rendered as “dev” and "{{ conf.get('workflow_owner') }}" is rendered as “service-principal://some-service-principal-dev“
- Conditional statement “{% if conf.get('failure_alerts') != None %} … {% endif %}” configures the different failure alert emails for each of the environments with the failure alert email addresses defined in the deployment variables file.
Step 5
Finally, render the Jinja template as a YAML file with all of the Jinja variables replaced by the their values.
python generate_deployment_file.py
The rendered YAML file is almost three times as long as the template file.
# conf/deployment.yaml
build:
no_build: true
environments:
dev:
workflows:
# DLT pipeline
- name: "dbx-dlt-demo-pipeline"
access_control_list:
- user_name: "service-principal://some-service-principal-dev"
permission_level: "IS_OWNER"
target: "demo-db"
workflow_type: "pipeline"
clusters:
- policy_id: "0123456789012345"
libraries:
- notebook:
path: "/Some/path/notebooks/sample_dlt_notebook"
# Workflow to orchestrate the whole data pipeline
- name: "dbx-demo-job"
workflow_type: "job-v2.1"
access_control_list:
- user_name: "service-principal://some-service-principal-dev"
permission_level: "IS_OWNER"
tasks:
- task_key: "pipeline-task"
pipeline_task:
pipeline_id: "pipeline://dbx-dlt-demo-pipeline"
test:
workflows:
# DLT pipeline
...
prod:
workflows:
# DLT pipeline
...
That’s it! Now we can deploy the workflows to dev, test, and prod, while maintaining only a single definition of workflows and tasks.
dbx deploy --environment <env>
Conclusion – Templating is a best practice
Using a template engine, such as Jinja, to dynamically generate dbx deployment files, has several advantages:
- Avoiding errors - Templating reduces the possibility of mistakes by keeping your code DRY (don’t repeat yourself). This, in turn, keeps your dbx deployment more manageable and keeps your developers happy by providing them with a better development experience.
- Identifying errors - Better yet, the rendered deployment file helps to spot possible mistakes in the templating process and, if necessary, we can always switch back to editing “deployment.yaml” directly.
- Better understanding – Avoiding repetition results in cleaner code that is easier to understand.
- Easy integration into the deployment process - Deployment files generated from templates are easily integrated into dbx deployments. Since templates are generated locally, they won’t affect your existing DevOps pipelines.
In this article, we discussed how to simplify dbx deployments across different environments using Jinja templates, which is only the tip of the iceberg of achieving successful, enterprise-level deployments to Databricks Lakehouses. There is so much more to discover. For example, you can create use-case-specific deployment templates with Cookiecutter to help developers kick-start new projects.
I hope you have enjoyed reading this guide. Here are a few links to help you master Databricks deployments:
- Source files used in this blog post
- Dbx by Databricks Labs
- Deployment file reference by dbx
- Basics of Jinja templating
- A handy VS Code extension for .j2 syntax highlighting
- Databricks asset bundles, an alternative for dbx deployments
Happy templating!